经常逛知乎,遇到好的回答 / 文章也会保存下来,但发现知乎有两个功能不是很喜欢,用油猴脚本解决了。
接下来介绍下这两个问题,以及原理,开发过程,开源地址等。
背景
作为一只数据仓鼠,我经常会保存互联网上的内容,其中就包括知乎上的回答。
但很多时候,这些回答会神秘地消失,只留下空荡荡的收藏夹……
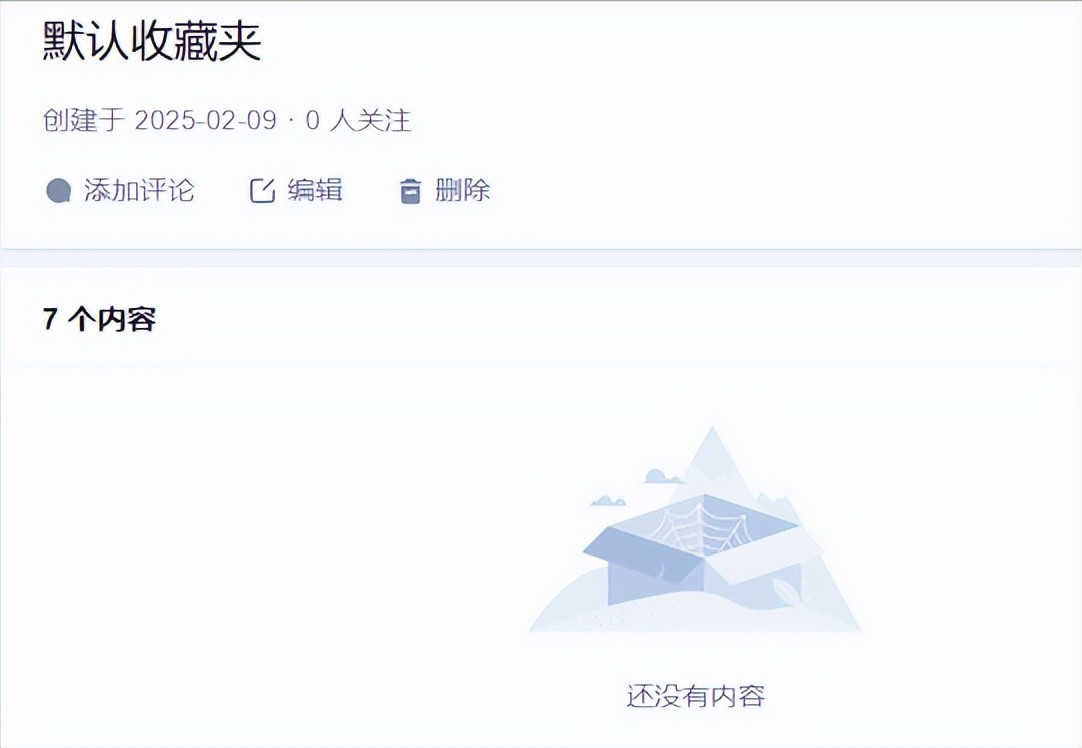
内容被删除了,但还是计数了(7 个),应该算 Bug?
所以,我会尽快将回答保存到自己的笔记软件。
但保存时,就经常遇到两个问题:一个是图片水印,一个是自动关键字链接。
由于没搜到类似的脚本,因此自己动手写了两个脚本,解决上述问题。
获取无水印原图
在知乎,默认情况下,用户上传的图片都是自动在右下角添加水印的(可以在设置 — 偏好设置里取消):

如果你查看网页源代码(F12),定位到图片,你会发现代码长这样,有很多的属性:

src 属性的值是图片链接(带用户水印的)。而 data-original-token 属性的值,和 src 里的图片文件名很相似,尝试用其替换掉 src 属性里的文件名,得到了无水印的原图:

PS:这个特性不是我发现的,而是看博主「致以无暇之人」的文章发现的:https://blog.elykia.cn/posts/17.html,在此表示感谢。
老实说,我虽然也是程序员,但我都没怎么看过网页的源代码,更别说定位到图片、发现其关联之处了,汗 😓
所以,开发思路就是,遍历网页上的所有图片,用 data-original-token 属性的值替换掉 src 属性值的文件名。
当然,如果用户上传的图片本身就带有水印,那么获取到的原图自然也是带水印的,但也不是没其他办法:
- 用去水印工具,例如谷歌新发布的 Gemini 2.0 Flash 模型,去除图片水印的效果极佳。
- 将图片保存下来,然后以图搜图。推荐我的另一篇博客:这应该是「以图搜图」最全教程了,能帮你找到 90% 的图片出处
移除自动关键字链接
很多平台,都会自动将用户内容中的关键字,替换为超链接。
例如知乎:
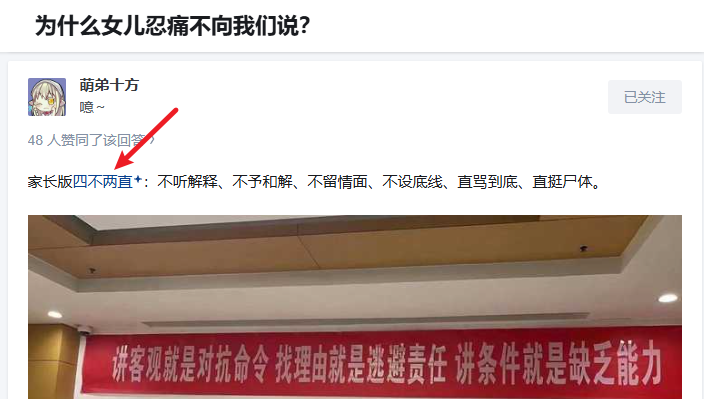
B 站:

点击这些超链接,就会在平台内搜索该关键字,某种程度上算方便了用户,但也影响了美观以及保存。
开发思路:用正则匹配超链接,然后替换为纯文本。
由于我不怎么保存其他平台的内容,所以该脚本仅针对知乎。
开发过程
首先,看了几个教程:
- 脚本猫上找到的 油猴开发指南:https://learn.scriptcat.org
- 篡改猴官方文档:https://www.tampermonkey.net/documentation.php
- Greasy Fork 上的帮助文档:https://greasyfork.org/zh-CN/help
然后看了开头几个文章,了解大概的编写过程,试着写了个 Hello World
然后直接问 DeepSeek,几分钟就写完了… (好像不用看教程也行?🙃)
只恨自己没早点写,老是手动去获取无水印原图(或者裁剪掉)、移除自动关键字链接,怪麻烦的 🤣。

开源和安装地址
代码都很简单,就不贴在文中了。
开源地址:https://github.com/Peter-JXL/UserScript
GreasyFork 地址:
- 知乎 – 获取无水印原图:https://greasyfork.org/zh-CN/scripts/531189
- 知乎 – 移除自动关键字链接:https://greasyfork.org/zh-CN/scripts/531190
测试案例:
- 油猴脚本测试文章 – 知乎:https://zhuanlan.zhihu.com/p/1888970134208639493,里面包含一张带水印的图片
- 为什么女儿忍痛不向我们说? – 知乎:https://www.zhihu.com/question/580630701/answer/119926368930,回答里包含带自动关键字链接
目前已在 Chrome、Edge、FireFox 上通过测试。
最后
自从我写《最全面的浏览器教程》以来,有不少人咨询过我,能否帮忙代写扩展 / 脚本之类的。
其实在 AI 时代,写脚本的门槛并不高,稍微看看教程,了解下开发过程,然后让 AI 给出代码即可。倒是写文档、发布脚本花了不少时间…
此外,即使你没有保存知乎回答的需求,这两个脚本也能美化下页面,水印和那些无用的超链接,很多时候没啥用。














评论前必须登录!
立即登录 注册